스키마란 데이터 자료의 구조, 자료의 표현 방법, 자료 간의 관계 정의한 데이터의 '구조'이다.
from pyspark.sql import SparkSession
sparkSession = SparkSession.builder.appName('spark_test_2').getOrCreate()
lines = sparkSession.read.csv('/home/hdoop/py-scripts/employee.csv')
print(type(lines))
lines = lines.toDF('id','name','salary','job')
lines.show()
lines.printSchema() #데이터의 구조를 보여준다.
위 코드는 반정형 데이터인 csv데이터를 DataFrame객체로 받아서 컬럼명을 설정하고
DataFrame에 저장된 값들과 스키마(데이터셋의 구조)를 출력한 것이다.
- id컬럼은 string(문자열) 값들이다.
- name컬럼은 string(문자열) 값들이다
- salary컬럼은 string(문자열) 값들이다
- job컬럼은 string(문자열) 값들이다
-> Schema구조를 따로 지정해주지 않아서 자동으로 모든 컬럼값들이 String(문자열)로 지정되어 있다.
- csv데이터는 nullable(null값의 유무)제어를 지원하지 않으므로 항상 nullable = true 이다.
- StructType()
#csv파일을 그냥 가져와도 데이터프레임에 자동으로 데이터 타입이 파악되어 저장할 수 있지만
#스키마의 구조를 정확하게 지정해서 데이터를 정확하게 다룰 수 있도록 스키마를 미리 지정한다
from pyspark.sql.types import * #pyspark.sql.types안에 있는 모든 자료형을 사용하겠다는 선언
idColumn = StructField('id',IntegerType(),nullable=False) #컬럼명 중에서 'id'는 Int 형이다 라는 정의, False : Null값 허용 X
nameColumn = StructField('name',StringType(),nullable=False) #컬럼명 중에서 'name'은 문자열 형이다 라는 정의, False : Null값 허용 X
salaryColumn = StructField('salary',IntegerType(), nullable=True) #컬럼명 중에서 'salary'는 Int형이다 라는 정의, True : Null값 허용 O
jobColumn = StructField('job',StringType(),nullable=True) #컬럼명 중에서 'job'dms 문자열 형이다 라는 정의, True : Null값 허용 O
empSchema = StructType([idColumn, nameColumn, salaryColumn, jobColumn]) #StructType()에 위에서 지정한 데이터 구조를 리스트에 담아서 지정하면
#데이터프레임에 대한 구조(스키마)를 저장한 것이다.
#데이터프레임과 구조(스키마) 연결하기
url = 'hdfs://localhost:9000/user/data/csv/employee_with_header.csv'
empDF = sparkSession.read.csv(path=url, header=True, schema=empSchema) #경로의 csv파일을 읽어서 header지정하고, 스키마는 우리가 위에서 지정한
#empSchema와 동일하게 지정된다
#Output : DataFrame[id: int, name: string, salary: int, job: string]
empDF.printSchema()
empDF.show()
스키마의 구조를 만들 때, pyspark모듈의 types를 이용한다.
- StructField('id', IntegerType(), nullable=False) : 'id' 컬럼 = Int타입, null값 거부(csv는 nullable 제어 불가)
- StructField('name',StringType(),nullable=False) : 'name' 컬럼 = String타입, null값 거부(csv는 nullable 제어 불가)
- StructField('salary',IntegerType(), nullable=True) : 'salary' 컬럼 = Int타입, null값 거부(csv는 nullable 제어 불가) - StructField('job',StringType(),nullable=True) : 'job' 컬럼 = String타입, null값 거부
-> 위에서 지정한 StructField() 객체들을 StructType() 객체 안에 담는다.
-> DataFrame 생성 시 schema = empSchema (StructType 객체)를 이용하면 미리 만들어논 스키마 구조를 DataFrame에 적용할 수 있다.
- InferSchema
# inferSchema=True : csv를 읽어올 때 데이터의 타입을 자동으로 파악하여 스키마 구조로 지정한다, inferSchema도 지정 안하면 기본 타입은 String이다. url = 'hdfs://localhost:9000/user/data/csv/employee_with_header.csv' empDF = sparkSession.read.csv(path=url, header=True, inferSchema=True) empDF.printSchema() empDF.show()
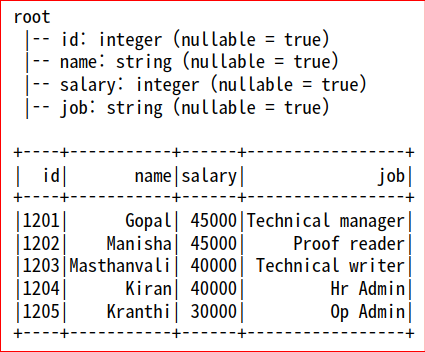
- DataFrame을 생성할 때, inferSchema=True 조건을 이용하면 각 컬럼의 데이터 형식을 자동으로 파악하여 스키마 구조를 지정할 수 있다.
- 위의 내용은 사전에 StructType()을 생성하지 않고 DataFrame 생성 시 inferSchema=True 조건만 주었을 때의 스키마 구조를 출력한 것이다. 데이터의 형식에 맞게 스키마가 적용된 것을 볼 수 있다.
'Hadoop' 카테고리의 다른 글
| DataFrame 가공/처리 함수(feat. Spark) (0) | 2021.09.20 |
|---|---|
| Spark로 Json파일 읽고 쓰기 (0) | 2021.09.16 |
| RDD -> DataFrame(feat. Spark) (0) | 2021.09.16 |
| RDD 가공/처리 함수 (0) | 2021.09.16 |
| RDD와 비정형데이터(feat. Spark) (0) | 2021.09.15 |




댓글