DataFrame 가공/처리 함수(feat. Spark)
Spark의 DataFrame에는 여러가지 함수들이 존재한다.
DataFrame에 들어있는 데이터를 처리/가공하기 쉽게 해주는 함수들이다.
이 함수들은 방대한 양의 데이터에서 필요한 정보만 필터링/추출 하는것이 매우 쉽다.
1. df.WithColumn()
- df.withColumn('col_name','new value') -> 특정 컬럼의 값을 new_value로 변경
2. df.select()
- df.select('col_name') -> 특정 컬럼 선택
3. df.filter()
- df.filter( ( df.col_name == 'Smith') & (...) ) -> 특정 행 선택 (조건을 여러개 붙힐때는 '&'를 사용한다)
4. df.drop()
- df.drop('col_name') -> 특정 컬럼 삭제
- df.drop('col1','col2','col3', ...) -> 여러개의 컬럼 삭제도 가능
예)
# employee.csv -> DataFrame 로드
# salary 30000 이하인 행 선택 / 급여를 10% 인상
ss = SparkSession.builder.getOrCreate()
path = 'hdfs://localhost:9000/user/data/csv/employee_with_header.csv'
df = ss.read.csv(path=path, header = True, inferSchema=True)
df.show()
#withColumn()함수만을 이용한 'salary'컬럼 10% 증가
#df2 = df.filter(df.salary <= 30000).withColumn('salary', df.salary * 1.1)
#df2.show()
#when() 함수
from pyspark.sql.functions import when
df2 = df.withColumn('salary', when(df.salary <= 30000, 33000) \
.when(df.salary > 30000, 100) \
.otherwise(df.salary))
#salary컬럼 값이 30000이하이면 33000으로 바꾸고
# salary컴럼 값이 30000 초과라면 100으로 바꾼다.
# 모든 경우가 아니면 그냥 둔다
df2.show()
#drop()함수
df3 = df2.drop('name') # name컬럼 삭제, 본 데이터프레임에서 삭제가 아닌 삭제된 새로운 DataFrame return
# ==
# df3 = df2.drop(df2.name)
# 여러개도 사용 가능
# df3 = df2.drop('name','salary')
# ==
# df3 = df2.drop(df2.name, df2.salary)
df3.show()
4. UDF : User Defined Function
- Spark에서 지원하는 사용자 지정 함수
- Annotation(주석) 활용
- 가능한한 최대한 Built-In함수를 사용하고 최후의 보루로서 사용하는 것을 권장
예 )
#UDF : User Defined Function
#Spark에서 지원하는 사용자 지정함수
# Annotation 활용
# 최대한 Built-In 함수를 사용하고 정말 방법이 없을 때 사용하는 것을 권장
from pyspark.sql.functions import udf #import udf
from pyspark.sql.types import *
@udf(StringType()) # Annotation을 사용하여 편리하게 UDF 선언, 함수의 return 타입은 String임
def sal_label(sal): # sal_label()함수 위에 @udf을 적어줌으로서
if sal<=3000 : return 'Low' # sal_label을 Spark DataFrame에서 사용 가능
elif sal<=40000 : return 'Middle'
else : return 'High'
# 사용 예시
df2 = df.withColumn('Sal Grade', sal_label(df.salary)) #'Sal Grade'라는 컬럼은 없으므로 새로 생성되고 값이 들어간다.
df2.show()
df2.write.csv('hdfs://localhost:9000/user/data/label/', mode='overwrite')
- Aggregation (agg) : 통계함수 = 집합함수(그룹함수)
* 사용법 : df.agg( { 'col_name' : function } ) - Json/Dict 형태를 지닌다
1. avg : 평균
2. max : 최대
3. min : 최소
4. sum : 합계
5. count : 계산
var : variance(분산)
6. var_samp (sample) - 통계학의 표본(sample) : 전체를 샘플링하여 일부를 추출
7. var_pop (population) - 통계학의 모집단(population) : 구하고자 하는 데이터셋의 전체
(stddev : 표준편차)
8. stddev_samp - 표본의 표준편차
9. stddev_pop - 모집단의 표준편차
예)
#급여의 최고액, 최저액, 평균액, 항목수 추출
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
res = df2.agg({'salary' : 'min'})
res.show()
df4 = df2.agg({'salary' : 'max'})
res.show()
df5 = df2.agg({'salary' : 'mean'})
res.show()
df6 = df2.agg({'salary' : 'count'})
res.show()
res = df.agg( max('salary'), min('salary'), mean('salary')) # 한 컬럼에 대해 여러개의 통계가 필요할 때 한번에 작성하는 법
res.show()
- csv파일을 읽은 뒤 함수를 사용할 때 (e.g. 계산을 요하는 함수들) 문자열 컬럼에 대한 적용 불가한 오류가 발생한다.그럴때는
1. 커스텀 스키마 적용
2. inferSchema = True 사용
3. DF 생성 후에 withColumn 사용하여 자료형 변경
-> e.g) df.withColumn('col1', df['col'].cast('double')) : 특정 컬럼의 Type을 Double로 선언
- 공분산 : 두 변수의 연관성 여부
df.cov('col', 'col2') << 두 컬럼의 공분산 구하는 법 - 상관계수 : 두 변수의 연관성의 크기 (-1 ~ +1)
df.corr('col','col2') << 두 컬럼의 상관계수 구하는 법
예)
from pyspark.sql.types import *
from pyspark.sql.functions import *
ss = SparkSession.builder.appName('diabetes').getOrCreate()
url = 'hdfs://localhost:9000/user/diabetes_info/diabetes.csv'
df = ss.read.csv(url, header=True, inferSchema = True) #inferSchema를 이용한 컬럼타입 사전 자동 설정
df.printSchema()
print(df.cov('Pregnancies', 'BloodPressure')) #두 컬럼 Pregnancies, BloodPressure의 공분산
print(df.corr('Pregnancies', 'BloodPressure')) # 두 컬럼 Prgnancies, BloodPressure의 상관계수
df2 = ss.read.csv(url,header =True)
df2.printSchema()
df2 = df2.withColumn('Pregnancies', df2.Pregnancies.cast('Double')) #withColumn()과 cast()함수를 이용한 컬럼 형변환
df2 = df2.withColumn('BloodPressure', df2.Pregnancies.cast('Double'))
df2.printSchema()



- 데이터를 탐색하는 방법으로 <기술통계>가 있다.
- 기술은 Describe의 의미를 가진다. 예) 특징을 기술하여라.
- df.describe()
- df.summary() : 사분위 포함
예 )
ss = SparkSession.builder.appName('describe').getOrCreate()
url = 'hdfs://localhost:9000/user/data/csv/employee4.csv'
df = ss.read.csv(url, header = True, inferSchema=True)
df.describe().show()
df.summary().show()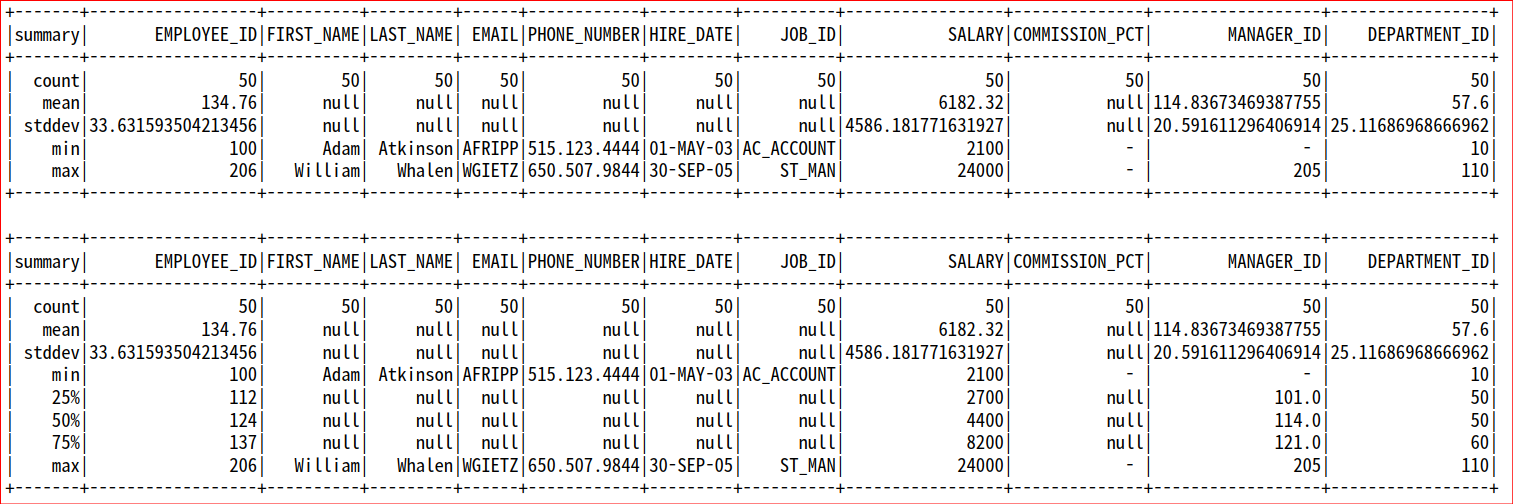
- df.orderBy('col_name') : 해당 컬럼 오름차순 정렬
- 여러개의 컬럼 정렬 : df.orderBy('col1','col2','col3'...)
- 내림차순 : df.orderBy('col_name', ascending=False)
- df.orderBy('col_name','col_name2', ascending=[True,False]) : col_name 오름차순, col_name2 내림차순, 맨 앞에 적힌 컬럼을 먼저 정렬, 값이 동일하면 뒤의 조건 순으로 정렬
예 )
#df3.orderBy('eid').show()
df3.orderBy(['department_id','eid'], ascending = [True,False]).show(df3.count())
- 중복제거
- df.drop_duplicates() : 중복 제거
- df.drop_duplicates(['col']) : col컬럼에 중복되는 값들을 첫번째를 제외하고 모두 제거
- df.drop_duplicates(['col','col2']) : col컬럼과 col2의 컬럼에 중복되는 값 제거
예)
#부서 번호가 중복되지 않고 한번만 출력
df3.drop_duplicates(['department_id']).show() # department_id 중복 값 제거
res = df3.drop_duplicates(['department_id']).orderBy(['department_id']) # department_id 중복 값 제거 후 오름차순 정렬
print("총 부서 수 : ", res.count())
res.show()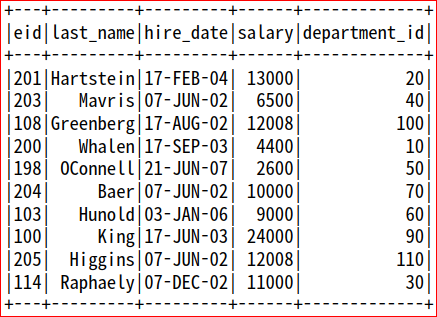

- 무작위 추출 : df.sample()
- 복원 추출 : df.sample(withReplacement = True) -> 임의의 값을 뽑고 그 다음값을 뽑을때 전에 뽑았던 값 포함하여 임의로 뽑는다
- 비복원 추출 : df.sample(withReplacement = False) -> 복원추출의 반대개념으로 임의의 값을 뽑으면 뽑힌 값은 제외하고 다음값을 뽑는다.
- fraction = 0.5 : 데이터셋중에서 50%를 뽑는다.
- seed = 10 : seed값을 10으로 하고 임의로 뽑는다. Random함수의 seed와 같은 개념
예)
#employee5.csv : 비복원 추출로 10개 급여평균, 모집단 급여평균 비교
# 비복원 추출 20%의 급여평균
sample = df.sample(withReplacement = False, fraction = 0.2, seed = 10)
sample.show()
#평균값 출력
sample.agg(avg('SALARY')).show()
#alias를 사용하면 예를 들어 SALARY에 대한 AVG를 출력할때 컬럼명을 지정할 수 있다.
sample.agg( avg('SALARY').alias('sample avg')).show()
# 모집단의 금여평균
df.agg({'SALARY' : 'mean'}).show()



- 특정 컬럼의 데이터 빈도수 구하는 함수 : df.freqItems(cols=['컬럼명', '컬럼명2','컬럼명3'...])
* Freaquancy(빈도수) Items(복수형)
예)
df.freqItems(cols = ['HIRE_DATE', 'DEPARTMENT_ID']).show() # 빈도수 순위
- 그룹화 : df.groupby(['컬럼1','컬럼2', ...]) + 계산 함수
-> 컬럼1, 컬럼2의 데이터값 별로 그룹화한다.
-> 그룹화된 그룹마다 계산함수를 이용하여 결과를 도출한다. 예) mean, max, min, count, etc.
예)
df.groupby(['DEPARTMENT_ID']).mean().orderBy('DEPARTMENT_ID').show() #부서별로 그룹화하여 그룹마다의 평균을 구하고 부서순으로 오름차순 정렬함